














Running the RAG API Server
Our RAG API leverages the vector database we built earlier and processes user queries using ChromaDB, LangChain, and OpenAI. It exposes a simple REST API endpoint that takes a query and returns a response enriched with Kubernetes documentation.
Quick Start
To run the server:
docker run -e OPENAI_API_KEY="<your-openai-key>" \
--volume /tmp/testcontainer:/tmp/testcontainer \
-p 8000:8000 \
--name rag_server_api rag_server_demo
Test it using curl:
curl -X 'POST' \
'http://0.0.0.0:8000/completion' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"query": "What is Kubernetes?"
}' | jq
Sample response:
{
"rag_response": "Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services..."
}
Expanding Knowledge Sources
Our RAG system is flexible, it can easily incorporate additional knowledge sources, such as:
- Customer-specific documentation
- Code repositories
- Logs and monitoring data
- Kubernetes audit and event logs
This extensibility makes RAG an ideal solution for advanced Kubernetes troubleshooting beyond generic LLM responses.
Enhancing K8sGPT with RAG
K8sGPT is an AI-powered Kubernetes troubleshooting tool that analyzes clusters and provides insights using Go-based analyzers. These analyzers detect common Kubernetes failure patterns and deliver structured diagnostic data.
By integrating our RAG API, K8sGPT can:
- Retrieve structured knowledge from Kubernetes documentation.
- Provide richer context when diagnosing issues.
- Minimize hallucinations by grounding responses in official documentation.
Setting Up K8sGPT with RAG
First, create a local Kubernetes cluster using Kind:
kind create clusterNext, deploy a broken pod to test troubleshooting capabilities:
apiVersion: v1
kind: Pod
metadata:
name: broken-pod
namespace: default
spec:
containers:
- name: broken-pod
image: nginx:1.a.b.c # Invalid image tag
livenessProbe:
httpGet:
path: /
port: 81
initialDelaySeconds: 3
periodSeconds: 3
Apply the configuration:
kubectl apply -f broken-pod.ymlClone and build the K8sGPT project with RAG integration:
git clone https://github.com/elieser1101/k8sgpt.git
cd k8sgpt
git checkout CustomRagAIClient
make build
This fork in the branch CustomRagAIClient contains a custom AI provider that allows K8sGPT to communicate with the RAG API. That’s why you’ll need to build the application from source.
Please feel free to explore the code to understand what happens under the hood.
Using K8sGPT’s Analyze and Explain Features
NOTE: Ensure you use the recently built k8sgpt, should be on ./bin/k8sgpt
Run the analyze command:
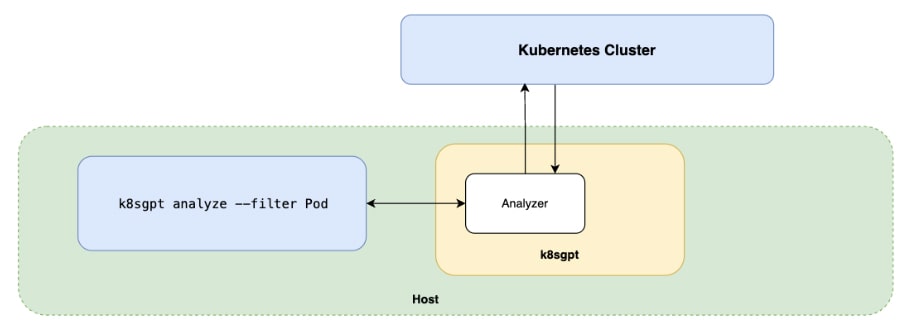
k8sgpt analyze --filter PodSample output:
AI Provider: AI not used; --explain not set
0: Pod default/broken-pod
- Error: Back-off pulling image "nginx:1.a.b.c"
It shows the error from pulling the image. You can also use the explain feature. This command utilizes any LLM provider (OpenAI, Llama, etc.) to explain the problem in natural language, based on the analyze results:
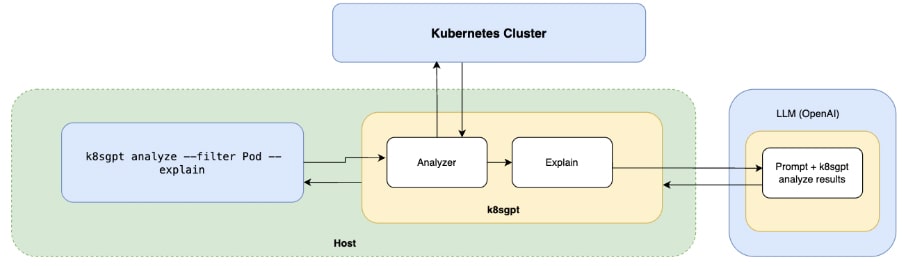
K8sGPT supports custom AI backends, allowing us to connect it to our RAG API.
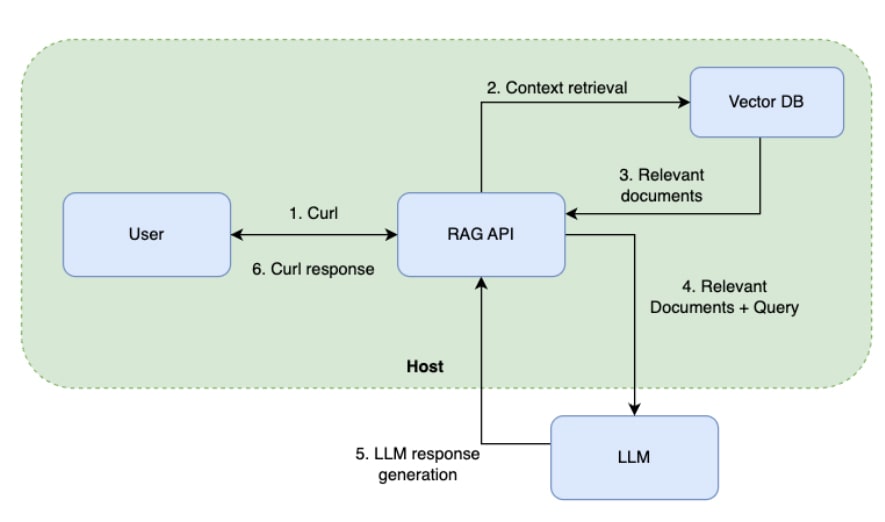
Final Architecture
Here’s the architecture of the complete system:
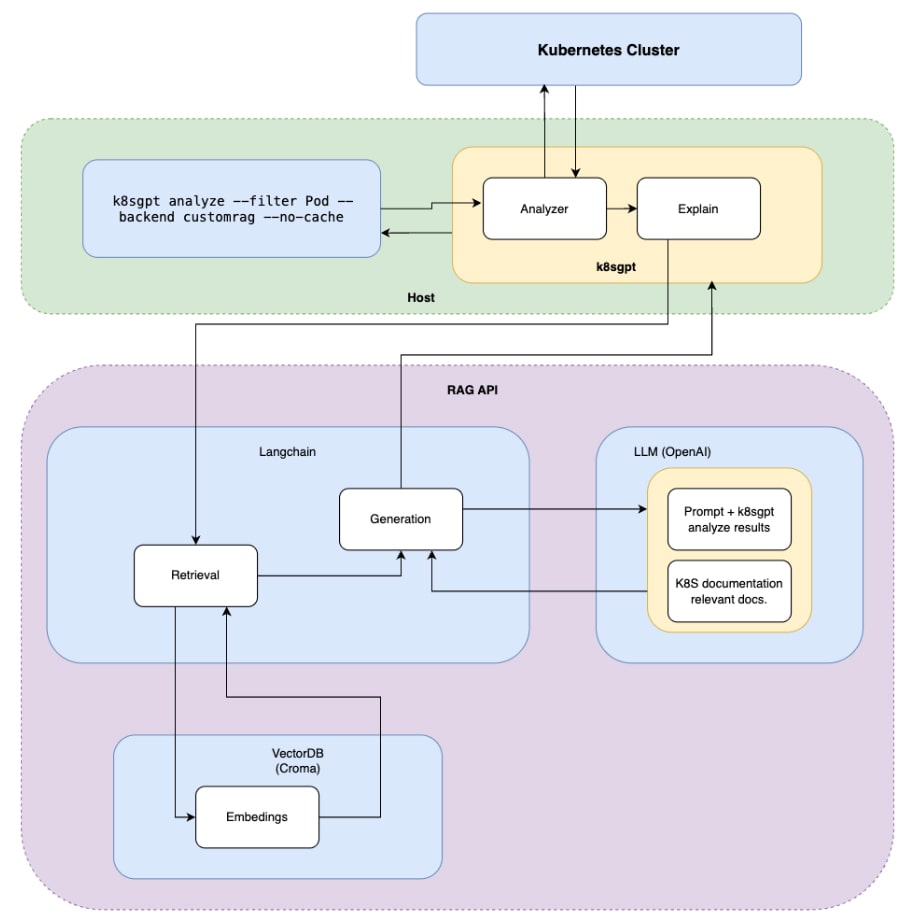
Running K8sGPT with the Custom RAG Backend
Add the custom RAG backend and run an analysis:
k8sgpt auth add --backend customrag
k8sgpt analyze --filter Pod --explain --backend customrag --no-cache
Example output:
0: Pod default/broken-pod
- Error: Back-off pulling image "nginx:1.a.b.c"
- Solution:
1. Check the image tag for typos.
2. Use a valid version (e.g., "nginx:1.16.1").
3. Run `kubectl set image deployment/nginx nginx=<correct_image_name>`.
How It Works
Here’s what happens under the hood:
- K8sGPT analyzes the cluster.
- As part of explain it sends an HTTP request to the RAG API.
- The RAG API retrieves relevant context/documentation from the vector database via LangChain.
- OpenAI processes the prompt, combining the analyze results and relevant documentation.
- K8sGPT displays accurate, contextualized troubleshooting insights.
Next Steps & Future Improvements
This system is already a powerful Kubernetes troubleshooting tool, but here’s how it can be improved:
- Deploy K8sGPT as a Kubernetes Operator to provide continuous monitoring and proactive alerts.
- Self-host an open-source LLM to reduce API costs and improve data privacy.
- Measure accuracy to minimize hallucinations and validate recommendations.
- Enable auto-remediation by integrating K8sGPT with Kubernetes controllers for self-healing clusters.
- Adopt the Model Context Protocol to standardize LLM context-sharing across tools.
- Package the solution as a SaaS product for small business with limited access to DevOps and SRE teams.
Conclusion
We’ve built a fully functional RAG system that enhances Kubernetes troubleshooting by combining:
✅ Kubernetes documentation embeddings
✅ A REST API powered by LangChain
✅ K8sGPT’s diagnostic capabilities
This combination makes Kubernetes issue resolution faster, more accurate, and grounded in official knowledge. With further development, this can evolve into a production-ready tool for SREs and platform engineers.
Explore our Cloud, SRE, DevOps & Cybersecurity solutions
With our Cloud, SRE, and DevOps Studio embrace cloud-native solutions for accelerated development, combined with reliable, secure, and scalable environments.


